JoJoGAN 实践
JoJoGAN: One Shot Face Stylization. 只用一张人脸图片,就能学习其风格,然后迁移到其他图片。训练时长只用 1~2 min 即可。
效果:

主流程:

本文分享了个人在本地环境(非 colab)实践 JoJoGAN 的整个过程。你也可以依照本文上手训练自己喜欢的风格。
准备环境
安装:
conda create -n torch python=3.9 -y
conda activate torch
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch -y
检查:
$ python - <<EOF
import torch, torchvision
print(torch.__version__, torch.cuda.is_available())
EOF
1.10.1 True
准备代码
git clone https://github.com/mchong6/JoJoGAN.git
cd JoJoGAN
pip install tqdm gdown matplotlib scipy opencv-python dlib lpips wandb
# Ninja is required to load C++ extensions
wget https://github.com/ninja-build/ninja/releases/download/v1.10.2/ninja-linux.zip
sudo unzip ninja-linux.zip -d /usr/local/bin/
sudo update-alternatives --install /usr/bin/ninja ninja /usr/local/bin/ninja 1 --force
然后,将本文提供的几个 *.py 放进 JoJoGAN 目录,从这里获取: https://github.com/ikuokuo/start-deep-learning/tree/master/practice/JoJoGAN 。
download_models.py: 获取模型generate_faces.py: 生成人脸stylize.py: 风格化train.py: 训练
之后,于训练流程一节,会结合代码,讲述下 JoJoGAN 的工作流程。其他些 *.py 只提下用法,实现就不多说了。
获取模型
python download_models.py 获取模型,如下:
models/
├── arcane_caitlyn_preserve_color.pt
├── arcane_caitlyn.pt
├── arcane_jinx_preserve_color.pt
├── arcane_jinx.pt
├── arcane_multi_preserve_color.pt
├── arcane_multi.pt
├── art.pt
├── disney_preserve_color.pt
├── disney.pt
├── dlibshape_predictor_68_face_landmarks.dat
├── e4e_ffhq_encode.pt
├── jojo_preserve_color.pt
├── jojo.pt
├── jojo_yasuho_preserve_color.pt
├── jojo_yasuho.pt
├── restyle_psp_ffhq_encode.pt
├── stylegan2-ffhq-config-f.pt
├── supergirl_preserve_color.pt
└── supergirl.pt
生成人脸
用 StyleGAN2 预训练模型随机生成人脸,用于测试:
python generate_faces.py -n 5 -s 2000 -o input
使用预训练风格
JoJoGAN 给了 8 个预训练模型,可以一并体验,与文首的效果图一样:
# 预览 JoJoGAN 所有预训练模型 风格化某图片(test_input/iu.jpeg)的效果
python stylize.py -i test_input/iu.jpeg -s all --save-all --show-all
# 使用 JoJoGAN 所有预训练模型 风格化所有生成的测试人脸(input/*)
find ./input -type f -print0 | xargs -0 -i python stylize.py -i {} -s all --save-all
训练自己的风格
首先,准备一张风格图:

之后,开始训练:
python train.py -n yinshi -i style_images/yinshi.jpeg --alpha 1.0 --num_iter 500 --latent_dim 512 --use_wandb --log_interval 50
--use_wandb 时,可查看训练日志:
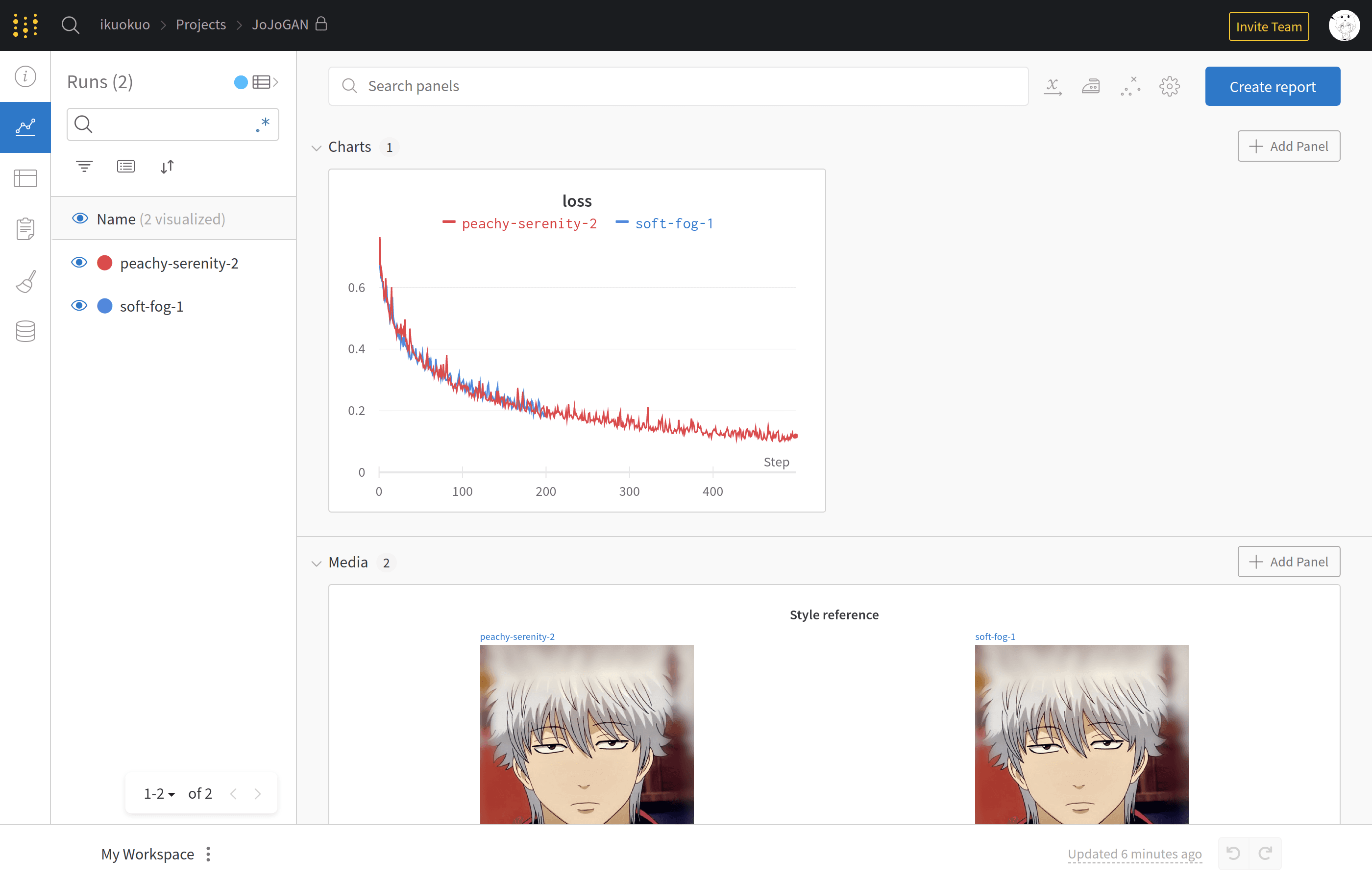
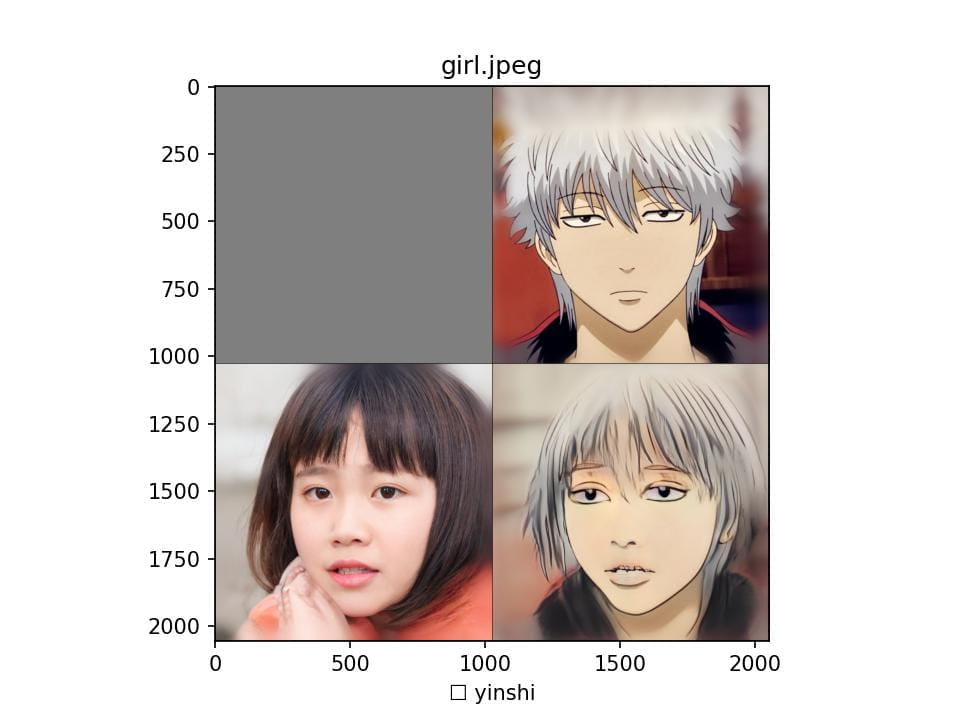
最后,测试效果:
python stylize.py -i input/girl.jpeg --save-all --show-all --test_style yinshi --test_ckpt output/yinshi.pt --test_ref output/yinshi/style_images_aligned/yinshi.png
训练工作流程
准备风格图片,转为训练数据
将风格图片里的人脸裁减对齐:
# dlib 预测人脸特征点,再裁减对齐
from util import align_face
style_aligned = align_face(img_path)
将风格图片 GAN Inversion 逆映射回预训练模型的隐向量空间(Latent Space):
name, _ = os.path.splitext(os.path.basename(img_path))
style_code_path = os.path.join(latent_dir, f'{name}.pt')
# e4e FFHQ encoder (pSp) > GAN inversion,得到 latent
from e4e_projection import projection
latent = projection(style_aligned, style_code_path, device)
载入 StyleGAN2 模型,训练微调
载入预训练模型:
latent_dim = 512
# 加载预训练模型
original_generator = Generator(1024, latent_dim, 8, 2).to(device)
ckpt = torch.load("models/stylegan2-ffhq-config-f.pt", map_location=lambda storage, loc: storage)
original_generator.load_state_dict(ckpt["g_ema"], strict=False)
# 准备微调的模型
generator = deepcopy(original_generator)
训练可调参数:
# 控制风格强度 [0, 1]
alpha = 1.0
alpha = 1-alpha
# 是否保留原图像色彩
preserve_color = True
# 训练迭代次数(最好 500,Adam 学习率是基于 500 次迭代调优的)
num_iter = 500
# 风格图片 targets 及 latents
targets = ..
latents = ..
进行训练,拟合隐空间。最后保存:
# 准备 LPIPS 计算 loss
lpips_fn = lpips.LPIPS(net='vgg').to(device)
# 准备优化器
g_optim = torch.optim.Adam(generator.parameters(), lr=2e-3, betas=(0, 0.99))
# 哪些层用于交换,用于生成风格化图片
if preserve_color:
id_swap = [7,9,11,15,16,17]
else:
id_swap = list(range(7, generator.n_latent))
# 训练迭代
for idx in tqdm(range(num_iter)):
# 交换层混合风格,并加噪声
mean_w = generator.get_latent(torch.randn([latents.size(0), latent_dim])
.to(device)).unsqueeze(1).repeat(1, generator.n_latent, 1)
in_latent = latents.clone()
in_latent[:, id_swap] = alpha*latents[:, id_swap] + (1-alpha)*mean_w[:, id_swap]
# 以 latent 风格化图片,与目标风格对比
img = generator(in_latent, input_is_latent=True)
loss = lpips_fn(F.interpolate(img, size=(256,256), mode='area'),
F.interpolate(targets, size=(256,256), mode='area')).mean()
# 优化
g_optim.zero_grad()
loss.backward()
g_optim.step()
# 保存权重,完成
torch.save({"g": generator.state_dict()}, save_path)
结语
JoJoGAN 实践下来效果不错。使用本文给到的代码,更容易上手训练自己喜欢的风格,值得试试。