视频结构化 AI 推理流程
「视频结构化」是一种 AI 落地的工程化实现,目的是把 AI 模型推理流程能够一般化。它输入视频,输出结构化数据,将结果给到业务系统去形成某些行业的解决方案。
换个角度,如果你想用摄像头来实现某些智能化监控、预警等,那么「视频结构化」可能就是你要用到的技术方案。
不过,也不一定需要自己去实现,因为各个芯片厂商可能都提供了类似的流程框架:
以上个人没用过,简单看了下,都受限于只能用厂商自家的芯片。个人经验来说,一般硬件还是需要多家可选的,自己实现一套「视频结构化」还是有必要的。
本文将介绍「视频结构化」的实现思路、技术架构,以及衍生的一些工作。
实现思路
有一个 AI 模型与一段视频,如何进行推理呢?
- 视频流:OpenCV 打开视频流,获取图像帧
- 前处理:图像 Resize 成模型输入的 Shape
- 模型推理:AI 框架进行模型推理,得到输出
- 后处理:将输出处理成期望的信息
- 例如,目标检测:解析框的位置和类别,再 NMS 筛选
以上是最基础的推理流程,完成得不错👏
简单任务,这样满足要求就行。但实际任务,可能:
- 输入
- 任务接收
- 视频流
- 相机选型
- 视频来源: 录制视频、RTSP 实时流
- 帧率控制: 一般 5 fps,减少计算
- 多路并发: 多路视频,并行分析
- 硬件解码
- 推理
- 前处理
- 输入调整: 缩放、转置
- Batch 合并
- 硬件加速
- 模型推理
- 硬件选型: Nvidia、华为昇腾、或其他
- 模型处理: 裁剪、转换、量化
- 模型编排: 多任务多模型,有先后关系
- 后处理
- 输出解析: 推理结果,变为结构化数据
- 硬件加速
- 前处理
- 输出
- 结果推送
- 其他
- 视频存储,License
- 链路追踪,耗时分析
以上流程一般称为「视频结构化」:输入多路视频,进行实时分析,最后输出结构化数据,给到业务系统。
该流程,这里把它分为了输入、推理、输出,都是一个个任务节点,整体采用 Pipeline 方式来编排 AI 推理任务。输入输出时,一般会用 RPC 或消息队列来与业务系统通信。
整体架构
「视频结构化」整体架构,如下:
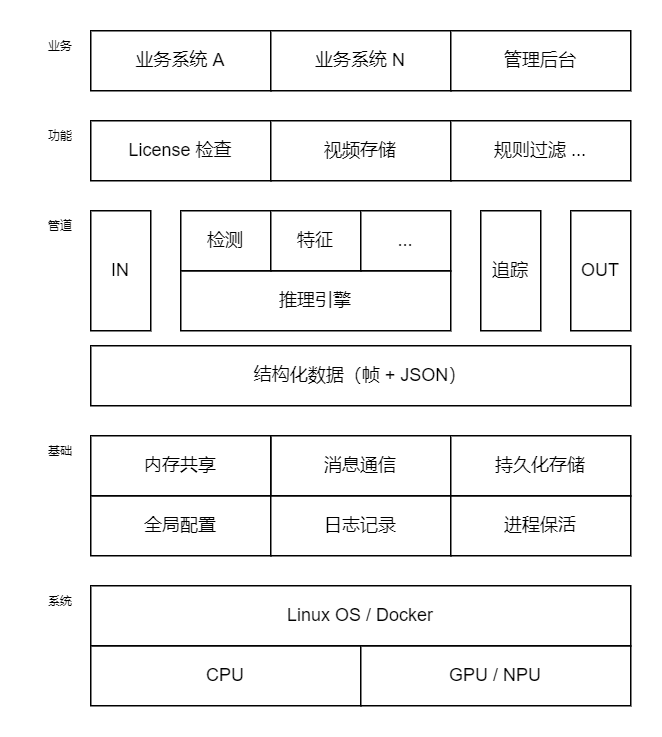
管道节点
管道 Pipeline 这块是主要部分,其实现都是一个个节点:
- IN
- 任务接收;视频流解码;帧率控制
- 推理
- 推理引擎做模型推理,结果进结构化数据;依编排往后继续
- 追踪
- 追踪依赖推理出的特征;业务不需要,就不编排
- OUT
- 结果推送;要预览播放的话,进行视频流编码
节点就是个生产消费者,用个阻塞队列很快就能实现。节点间组成一个树,也就是任务编排的结果。节点会有输入输出差异,要约定清楚或分几个类型。
节点流程:消息队列有任务,取出执行,结果进结构化数据,最后发给下一节点的消息队列。
节点的线程数、队列上限,都可做配置。依据耗时分析,可以优化调整。
GStreamer 的 pipeline + plugin 的技术架构值得学习。个人没深入了解,所以不好具体评价,倒见过在输入做插件化解码。NVIDIA DeepStream 直接就基于 GStreamer 开发的。
结构数据
结构化数据,在整个 Pipeline 里是不断追加完善的过程,最后输出时一般 JSON 化推送。
它的内容约定,是最主要的。会有:
- 基础信息: task, frame 等信息
- 推理结果: 会以任务分类进行标签
它会用作节点的输入,例如获取人脸特征,依赖前一目标检测节点的人脸 boxes 信息。
基础模块
- 全局配置
- 通用配置、节点配置与编排;可视化编排,实际就是编辑它
- 一般 JSON 格式,结构化数据最后也 JSON 化
- 进程保活
- Supervisor 不错,可以把终端日志配置进文件
- 消息通信
- 与外部系统,用 RPC 或 Redis,也可能推送 Kafka
- 内部用自己的消息队列
- 内存共享
- 用在图像帧,以免拷贝,帧 ID 标识
- 显存也预申请,队列分配,减少 Host & Device 拷贝
技术选型
「视频结构化」用 C++ 实现,主要以下几点:
- FFmpeg 编解码(CPU)
- OpenCV 前后处理(CPU)
- 芯片生态库,硬件加速:编解码与前后处理
- 如 Nvidia: video codec, npp, nvjpeg; 昇腾 dvpp 等
- 基础库,选择主流的就好,如:
- Log:gabime/spdlog, google/glog
- JSON: nlohmann/json
- RPC: grpc/grpc, apache/incubator-brpc
更详细的技术栈,可见该分享:https://zhuanlan.zhihu.com/p/362711954 ,思维导图很详细。
「视频结构化」实现有些要看自己的权衡:
- 一个项目怎么支持多个硬件?
- 编译自动区分环境,编译不同代码,最终会产生多套部署
- 需要抽象推理、前后处理等硬件相关功能
- 也可以考虑插件实现,管理好插件配置
- 编译自动区分环境,编译不同代码,最终会产生多套部署
- 视频流要不要用流媒体框架?
- 简单点直接 FFmpeg,不引入 GStreamer
- 图像与结果怎么优化同步?
- 只是图像显示,存储提供链接进结果(注意 IO 瓶颈)
- 本身视频显示,直接绘制结果进图像,编码进流
- 或预览端自己实现,流数据包携带结果
衍生工作
「视频结构化」会有一些衍生的工作:库、工具或系统。
首先,模型一般自定义格式,一是保护,二是方便自己使用。所以,会把原模型及其配置封装进自定义格式,还会标明推理方式、前后处理选择等。
这里会有如下两个部分:
- 模型转换工具链: 不同硬件模型转换后,再封装进自己格式
- 模型推理引擎: 模型解封装,再依配置进行推理,出结果
模型可能还要裁剪、量化,也是工作的一部分。
其次,任务情况、JSON 配置、日志等,成熟一点,还会提供管理后台方便使用。
此外,还可能有:
- License: 生成、校验相关工具,及管理记录
- 除了有效期,还可以考虑限制路数、任务等
- 实时监控: 硬件状态监控、预警
结语
「视频结构化」只是 AI 落地的一部分,实际做方案一是对接算法模型、二是对接业务系统,还可能要去适配新的摄像头或硬件平台。
也就是会有两种支持列表:硬件列表、模型列表。这就是积累的成果了。
「视频结构化」会部署成中心服务器,或边缘计算。不过,只是简单任务,现在可能智能摄像头就够了,都带边缘计算识别人脸什么的。