YOLOv4 Docker 使用
YOLO 算法是非常著名的目标检测算法。从其全称 You Only Look Once: Unified, Real-Time Object Detection ,可以看出它的特性:
- Look Once: one-stage (one-shot object detectors) 算法,把目标检测的两个任务分类和定位一步完成。
- Unified: 统一的架构,提供 end-to-end 的训练和预测。
- Real-Time: 实时性,初代论文给出的指标 FPS 45 , mAP 63.4 。
YOLOv4: Optimal Speed and Accuracy of Object Detection ,于 2020 年 4 月公布,采用了很多近些年 CNN 领域优秀的优化技巧。其平衡了精度与速度,目前在实时目标检测算法中精度是最高的。
论文地址:
源码地址:
本文将介绍 YOLOv4 官方 Darknet 实现,如何于 Docker 编译使用。以及从 MS COCO 2017 数据集中怎么选出部分物体,训练出模型。
准备 Docker 镜像#
首先,准备 Docker ,请见:Docker: Nvidia Driver, Nvidia Docker 推荐安装步骤 。
之后,开始准备镜像,从下到上的层级为:
- nvidia/cuda: https://hub.docker.com/r/nvidia/cuda
- OpenCV: https://github.com/opencv/opencv
- Darknet: https://github.com/AlexeyAB/darknet
nvidia/cuda#
准备 Nvidia 基础 CUDA 镜像。这里我们选择 CUDA 10.2 ,不用最新 CUDA 11,因为现在 PyTorch 等都还都是 10.2 呢。
拉取镜像:
测试镜像:
OpenCV#
基于 nvidia/cuda 镜像,构建 OpenCV 的镜像:
其 Dockerfile 可见这里: https://github.com/ikuokuo/start-yolov4/blob/master/docker/ubuntu18.04-cuda10.2/opencv4.4.0/Dockerfile 。
Darknet#
基于 OpenCV 镜像,构建 Darknet 镜像:
其 Dockerfile 可见这里: https://github.com/ikuokuo/start-yolov4/blob/master/docker/ubuntu18.04-cuda10.2/opencv4.4.0/darknet/Dockerfile 。
上述镜像已上传 Docker Hub 。如果 Nvidia 驱动能够支持 CUDA 10.2 ,那可以直接拉取该镜像:
准备 COCO 数据集#
MS COCO 2017 下载地址: http://cocodataset.org/#download
图像,包括:
- 2017 Train images [118K/18GB]
- 2017 Val images [5K/1GB]
- 2017 Test images [41K/6GB]
- 2017 Unlabeled images [123K/19GB]
标注,包括:
- 2017 Train/Val annotations [241MB]
- 2017 Stuff Train/Val annotations [1.1GB]
- 2017 Panoptic Train/Val annotations [821MB]
- 2017 Testing Image info [1MB]
- 2017 Unlabeled Image info [4MB]
用预训练模型进行推断#
预训练模型 yolov4.weights ,下载地址 https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights 。
运行镜像:
进行推断:
推断结果:

准备 COCO 数据子集#
MS COCO 2017 数据集有 80 个物体标签。我们从中选取自己关注的物体,重组个子数据集。
首先,获取样例代码:
- scripts/coco2yolo.py: COCO 数据集转 YOLO 数据集的脚本
- scripts/coco/label.py: COCO 数据集的物体标签有哪些
- cfg/coco/coco.names: 编辑我们想要的那些物体标签
之后,准备数据集:
数据集,内容如下:
训练自己的模型并推断#
准备必要文件#
cfg/coco/coco.names <cfg/coco/coco.names.bak has original 80 objects>
- Edit: keep desired objects
cfg/coco/yolov4.cfg <cfg/coco/yolov4.cfg.bak is original file>
- Download yolov4.cfg, then changed:
batch=64,subdivisions=32 <32 for 8-12 GB GPU-VRAM>width=512,height=512 <any value multiple of 32>classes=<your number of objects in each of 3 [yolo]-layers>max_batches=<classes*2000, but not less than number of training images and not less than 6000>steps=<max_batches*0.8, max_batches*0.9>filters=<(classes+5)x3, in the 3 [convolutional] before each [yolo] layer>`filters`=<(classes+9)x3, in the 3 [convolutional] before each [Gaussian_yolo] layer>
- Edit:
train,validto YOLO datas
- Edit:
csdarknet53-omega.conv.105
- Download csdarknet53-omega_final.weights, then run:
训练自己的模型#
运行镜像:
进行训练:
中途可以中断训练,然后这样继续:
yolov4_last.weights 每迭代 100 次,会被记录。
如果多 GPU 训练,可以在 1000 次迭代后,加参数 -gpus 0,1 ,再继续:
训练过程,记录如下:
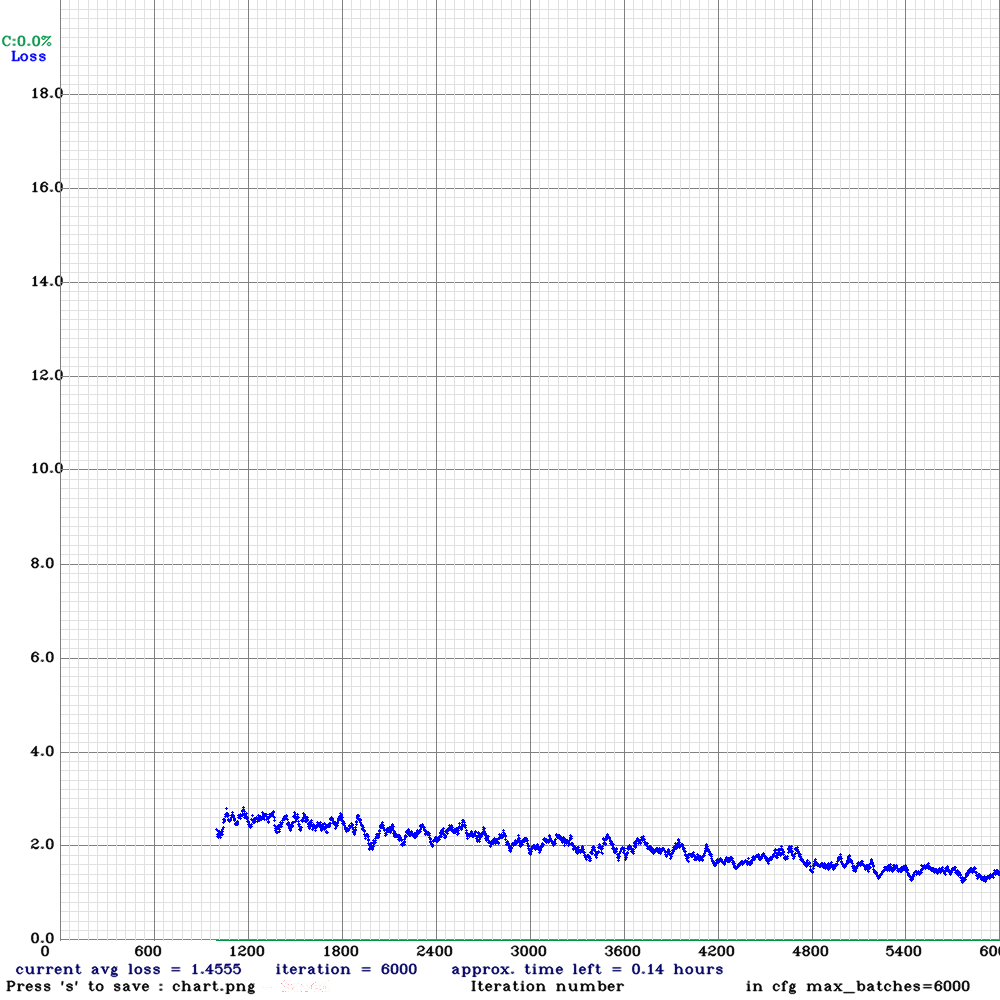
加参数 -map 后,上图会显示有红线 mAP。
查看模型 mAP@IoU=50 精度:
进行推断:
推断结果:

参考内容#
- Train Detector on MS COCO (trainvalno5k 2014) dataset
- How to evaluate accuracy and speed of YOLOv4
- How to train (to detect your custom objects)
结语#
Docker 可导出镜像,简化环境部署。如 PyTorch 也都有镜像,可以直接上手使用。
Darknet 直接于 Ubuntu 编译,及使用 Python 接口,可见《YOLOv4 Ubuntu 使用》。