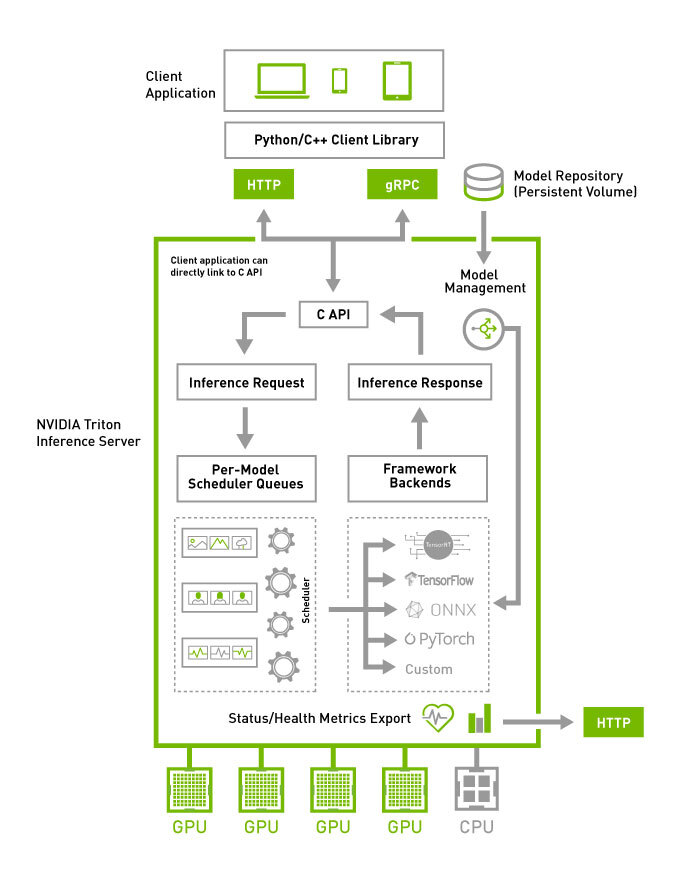
NVIDIA Triton
· 阅读需 1 分钟

NVIDIA Triton Inference Server provides an optimized cloud and edge inferencing solution.
NVIDIA Triton 是一个高性能的推理服务器,通过深度优化硬件利用率和并发处理能力,为云端和边缘提供超低延迟、高吞吐的模型推理服务。
它通过 Ensemble Models(模型集成)功能来实现多模型工作流,这是一种“服务器内部、紧密耦合”的流水线编排。支持 KServe 协议。
侧重极致性能和硬件优化,尤其适合生产级高吞吐、低延迟场景。
https://github.com/triton-inference-server/server