MediaPipe
· 阅读需 1 分钟

MediaPipe: cross-platform, customizable ML solutions for live and streaming media.
侧重端侧模型解决方案与部署。支持视觉、文本、音频和LLM任务,且每种任务都包含一个或多个模型,可部署 Android, iOS, Web 等。
https://github.com/google-ai-edge/mediapipe
MediaPipe: cross-platform, customizable ML solutions for live and streaming media.
侧重端侧模型解决方案与部署。支持视觉、文本、音频和LLM任务,且每种任务都包含一个或多个模型,可部署 Android, iOS, Web 等。
https://github.com/google-ai-edge/mediapipe
VideoPipe: 跨平台的视频结构化(视频分析)框架。适用于视频结构化、图片搜索、人脸识别、交通/安防领域的行为分析(如交通事件检测)等场景。
模型推理: 默认采用OpenCV::DNN实现。如果要适配其他硬件平台,比如瑞芯微的RKNN、华为的CANN等,需要参考其厂家提供的推理Demo代码,将其封装成VideoPipe中的一个推理Node即可。
侧重视频分析,包含拉流、推流等,适合快速集成与落地。
https://github.com/sherlockchou86/VideoPipe

nndeploy: 一款简单易用和高性能的AI部署框架。基于可视化工作流和多端推理,可让 AI 算法在上述平台和硬件更高效、更高性能的落地。
侧重端侧部署,包含:桌面端(Windows、macOS)、移动端(Android、iOS)、边缘计算设备(NVIDIA Jetson、Ascend310B、RK 等)以及单机服务器(RTX 系列、T4、Ascend310P 等)。
https://github.com/nndeploy/nndeploy

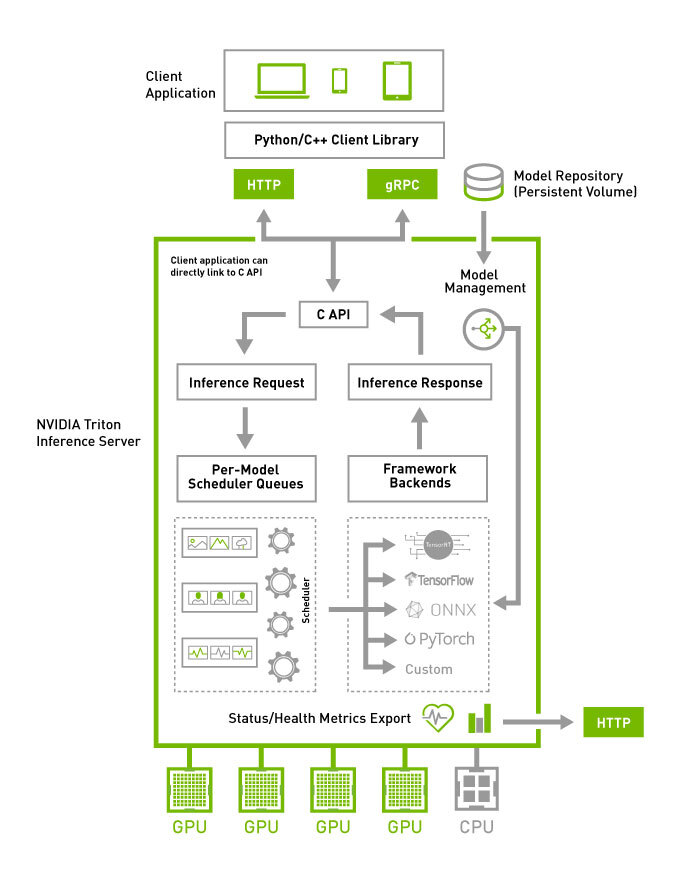
NVIDIA Triton Inference Server provides an optimized cloud and edge inferencing solution.
NVIDIA Triton 是一个高性能的推理服务器,通过深度优化硬件利用率和并发处理能力,为云端和边缘提供超低延迟、高吞吐的模型推理服务。
它通过 Ensemble Models(模型集成)功能来实现多模型工作流,这是一种“服务器内部、紧密耦合”的流水线编排。支持 KServe 协议。
侧重极致性能和硬件优化,尤其适合生产级高吞吐、低延迟场景。
https://github.com/triton-inference-server/server